

Testy bezpieczeństwa przy okazji testów manualnych, czyli jak łagodnie rozpocząć przygodę z cybersec.
O tym jak bardzo ważnym aspektem branży IT, jak i życia codziennego każdego z nas, jest bezpieczeństwo danych, nie trzeba chyba nikogo specjalnie przekonywać. Zwłaszcza od czasu wprowadzenia powszechnie znanych już, regulacji RODO/GDPR. Znamy liczne przypadki wycieków danych z popularnych serwisów, które przez zaniedbania, niefrasobliwość, krótkowzroczność lub po prostu nieświadomość autorów skutkowały poważnymi konsekwencjami, pozwami lub wysokimi odszkodowaniami. Tempo rozwoju nowych technologii i rozwiązań systematycznie wzrasta, niosąc ze sobą niestety, ciężkie brzemię potencjalnych, niezbadanych podatności. Dlatego łatwo przewidzieć, że zapotrzebowanie na specjalistów branży security będzie stale rosło. To idealny moment, aby rozpocząć swoją przygodę z szeroko pojętym testowaniem bezpieczeństwa lub przynajmniej poszerzyć swoją wiedzę o jego podstawowe elementy.
W niniejszym artykule, chciałbym przedstawić kilka pomysłów, na to jak w prosty sposób, poszerzyć zakres swoich działań podczas testów manualnych po to, aby zadbać o kwestie bezpieczeństwa oraz zaoferować klientowi pewną wartość dodaną. Dzięki niej, nie tylko zyskasz w oczach samego klienta, ale także przygotujesz swojemu pracodawcy potencjalny grunt do rozmów o ewentualnym poszerzeniu współpracy z klientem (np. o testy penetracyjne) za co z pewnością zostaniesz doceniony.
Nie będzie to ekspercki tekst, wyjaśniający szczegółowo techniczne aspekty cyberbezpieczeństwa. Zakładam, że jako tester posiadasz podstawową wiedzę o tym, czym są np. ciasteczka (cookies), jak posługiwać się narzędziami deweloperskimi w przeglądarce (Devtools) lub jak (mniej więcej) odbywa się komunikacja HTTP.
Chciałbym podzielić się z Tobą zbiorem pomysłów i dobrych praktyk, wykorzystywanych w mojej codziennej pracy, których nauczyłem się w trakcie blisko trzyletniej kariery testerskiej, którą w ostatnim czasie postanowiłem skierować w stronę cybersec.
Ważna uwaga na początek
Zanim przejdę do sedna, chciałbym zwrócić Twoją uwagę na bardzo istotną rzecz. Kwestie związane z bezpieczeństwem to bardzo delikatny temat. Często nawet niewinne majstrowanie lub ingerencja w aplikację mogą być niezgodne z prawem. Przed rozpoczęciem jakichkolwiek działań związanych z testowaniem bezpieczeństwa upewnij się czy Twój klient wyraża na nie zgodę oraz czy ich zakres nie wykracza poza ramy przez niego ustalone. Pamiętaj, że nawet po otrzymaniu zgody na testy, poznanie danych prawdziwych klientów (np. na środowisku produkcyjnym), może być bardzo problematyczne w kontekście RODO, dlatego bądź zawsze ostrożny. Jeśli podejrzewasz, że w aplikacji występuje podatność, dzięki której jeden użytkownik może zobaczyć dane drugiego - użyj dwóch kont testowych.
Szczególną ostrożność zachowaj podczas wszelkich prób wprowadzania nietypowych danych wejściowych do aplikacji (XSS, SQLi itp) lub modyfikacji zapytań kierowanych do serwera.
Uzyskanie dostępu do danych, do którego nie jesteś uprawniony to nie jedyny problem jaki może pojawić się podczas testów. Innym przykładem może być czasowe lub trwałe uszkodzenie danych lub aplikacji czy infrastruktury. Działaj rozsądnie i etycznie oraz informuj o swoich zamiarach, aby uniknąć nieprzyjemnych niespodzianek w stylu wiadomości o treści: „Dziękujemy za niezamówione testy penetracyjne. Do zobaczenia wkrótce.”
Komentarze w kodzie
Analizuj kod źródłowy strony pod kątem pozostawionych przez deweloperów komentarzy. Mogą być one źródłem cennych informacji dla potencjalnego atakującego. Zdarzają się sytuacje, w których przez pośpiech lub nieuwagę, do środowiska produkcyjnego przedostają się komentarze z opisami działania funkcji, danymi logowania lub linkami do środowisk deweloperskich.

Przykład z życia: w kodzie jednej ze stron pewnego serwisu, znalazłem komentarz zawierający link do repozytorium, w którym trwała dyskusja na temat sposobu naprawy poważnego błędu, który wciąż nie był wyeliminowany.
Oczywiście ręczne przeglądanie każdej podstrony może być bardzo czasochłonne. Na szczęście istnieją narzędzia, które pomagają przyspieszyć ten procesu. Zazwyczaj bazują one na wyrażeniach regularnych (RegEx), które przy odpowiedniej konstrukcji, wyszukują w kodzie znaczniki komentarzy.
Ukryte elementy
Oprócz komentarzy w kodzie możemy napotkać także różnego rodzaju elementy z parametrami: visibility:hidden lub display:none. Warto zwracać na nie uwagę i próbować wyświetlić je na stronie zmieniając wartości ich parametrów za pomocą Devtools (zakładka Element). Czasami deweloperzy przez lenistwo lub brak czasu na prawidłową implementację ukrywają niektóre, istotne z punktu widzenia bezpieczeństwa, elementy, licząc, że zwykły użytkownik ich nie znajdzie. Czasami można znaleźć tam bardzo ciekawe rzeczy.
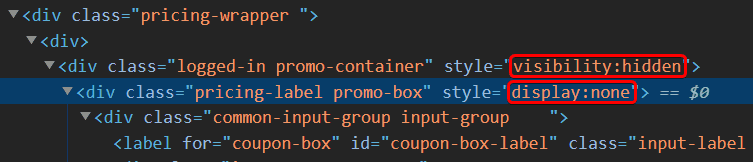
Polecam ciekawe narzędzie o nazwie Web Developer dostępne jako add-on dla przeglądarek Chrome, Firefox i Opera pod adresem: https://chrispederick.com/work/web-developer/. Jest to zbiór bardzo wielu przydatnych narzędzi, wśród których znajdziesz m.in opcję „Display Hidden Elements”, która pomoże Ci wyświetlić ukryte elementy strony.

Logika działania kodów rabatowych
Szukaj błędów w logice działania mechanizmów obsługujących kody rabatowe. Bądź sprytny i kreatywny. Przeanalizuj sposób działania mechanizmu, a następnie spróbuj znaleźć jego obejście sprawdzając np.:
- czy raz wykorzystany kod można użyć ponownie w kolejnych zamówieniach,
- czy ten sam kod można zastosować więcej niż jeden raz w danym zamówieniu zwielokrotniając tym samym kwotę rabatu,
- co się stanie, gdy szybko klikniesz dwukrotnie przycisk aplikowania kodu,
- czy da się zastosować więcej niż jeden kod w danym zamówieniu,
- jeśli do użycia kodu wymagana jest kwota minimalna zamówienia, dodaj odpowiednie produkty, użyj kodu, a następnie usuń część produktów,
- czy da się odgadnąć inny kod na podstawie już znanego np. RABAT10 > RABAT50,
- sprawdź czy po zastosowaniu kodu i usunięciu produktu, wartość zamówienia nie zmieni się na wartość ujemną,
- jeśli posiadasz dwa kody rabatowe „X” i „Y”, a każdy z nich możesz użyć teoretycznie tylko raz — sprawdź czy uda się je wykorzystać stosując jedną z sekwencji XXYY, YYXX, XYXY, YXYX,
- czy po wpisaniu kodu i przejściu do kolejnego kroku w procesie zakupowym, da się wrócić do poprzedniego kroku i jeszcze raz aktywować kod (ten sam lub inny).
Przykładów może być mnóstwo. Wszystko zależy od specyfiki danej aplikacji.
Przykład z życia: na stronie pewnej znanej firmy, można było wykorzystać kod rabatowy. Gdy kod został zaaplikowany w jednej rezerwacji, a użytkownik chciał utworzyć kolejną i zaaplikować w niej ten sam kod po raz kolejny nie było to możliwe, ponieważ front-end nie wyświetlał już pola do wpisaniu kodu w drugiej rezerwacji. Sposób obejścia tego mechanizmu był banalny. Wystarczyło stworzyć dwie rezerwacje w osobnych kartach przeglądarki zanim kod został użyty. Tak, aby w obu oknach przycisk i pole do aplikowania kodu były widoczne. Następnie, w obu oknach należało wpisać ten sam kod i zatwierdzić go za pomocą przycisku. W obu rezerwacjach kod był aplikowany poprawnie.
Błędy logiczne w procesie zakupowym
Błędy logiczne pojawiają się także w przypadku akcji związanych z samym procesem zakupowym, takich jak dodawanie produktu do koszyka czy zmian ilości zamawianych sztuk. Warto również i tutaj wykazać się pomysłowością. Oto kilka przykładowych działań, które mogą doprowadzić do dziwnych anomalii:
- Spróbuj zmienić ilość produktu na wartość ujemną pamiętając że czasami jest to możliwe na kilka sposobów. Na przykład za pomocą przycisków +/-, wpisując wartość za pomocą klawiatury lub przy pomocy listy wyboru. Jeśli na liście wyboru nie ma wartości ujemnej możesz podmienić ją w kodzie, za pomocą Devtools lub przechwytując request w locie (np. za pomocą Burp Suite) i podmieniając wartość odpowiedniego parametru. Na koniec zatwierdź zmiany w zamówieniu, jeśli jest to wymagane do jego zaktualizowania. Sprawdź jak zachowa się cena. Bardzo często w takich sytuacjach, koszt całkowity zamówienia również zmienia się na wartość ujemną;
- Spróbuj dodać bardzo dużą ilość danego produktu do koszyka. Nie chodzi tutaj o 50 telewizorów, a raczej 99999, 2147483648 czy 4294967295 itp. Dwie ostatnie wartości, to akurat przekroczone o 1, limity wartości typów zmiennych INT_MAX oraz UINT_MAX w języku C++. Oczywiście, to czy wystąpią jakieś nieprawidłowości, po wpisaniu tego rodzaju wartości zależy m.in od wykorzystanych w aplikacji typów zmiennych oraz ich prawidłowego obsłużenia. Bywają sytuacje, w których po przekroczeniu pewnej liczby produktów z ceną zaczynają dziać się dziwne rzeczy;
- Bazując na poprzednim przykładzie sprawdź, czy da się przekroczyć jakąś wartość graniczną w przypadku ceny. Jeśli ilość sztuk danego produktu jest limitowana, dodaj inne przedmioty, tak aby zwiększyć całkowity koszt zamówienia do jak największej wartości;
- Sprawdź jak zachowa się aplikacja, jeśli jako ilość sztuk danego produktu wprowadzisz nietypową wartość zawierającą przecinek, kropkę lub znak działania np: ,01; 01; 01,; 0,11; .01; 01.; 0.11; 0-3; .0-3; .1
-
- Jeśli nie osiągnąłeś wartości minimalnej zamówienia i przycisk „Przejdź do płatności” jest nieaktywny, otwórz Devtools (zakładka Elements), zlokalizuj przycisk i zmień jego atrybut z disabled na enabled lub po prostu go usuń, a następnie kliknij ponownie. Źle zaimplementowany mechanizm (np. brak odpowiedniej weryfikacji po stronie back-endu), przepuści takie żądanie.
Przykład z życia: w pewnym serwisie zwykły użytkownik po zalogowaniu się, miał dostęp do panelu, w którym mógł napisać artykuł. Po jego ukończeniu, mógł zapisać zmiany i kliknąć przycisk „Wyślij do zatwierdzenia”. Tuż obok znajdował się przycisk „Opublikuj”, który był nieaktywny. Był przeznaczony dla użytkownika z uprawnieniami moderatora. Jak łatwo się domyślić, wystarczyło zmienić atrybut przycisku z disabled na enabled i go kliknąć. Artykuł natychmiast zostawał opublikowany.
Nagłówki bezpieczeństwa
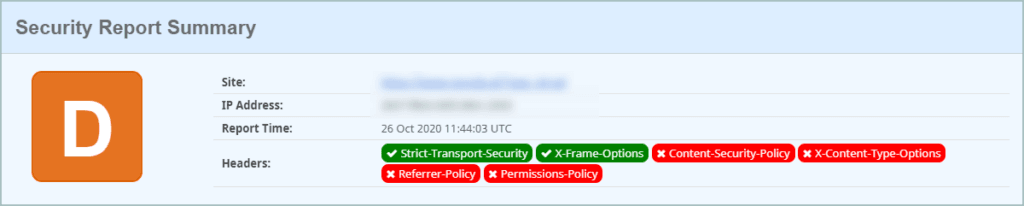
Upewnij się czy aplikacja korzysta z nagłówków bezpieczeństwa takich jak m.in:
- Strict-Transport-Security,
- X-Frame-Options,
- Content-Security-Policy,
- X-Content-Type-Options,
- Referrer-Policy,
- Permissions-Policy,
- X-XSS-Protection.
Możesz to sprawdzić analizując odpowiedzi serwera za pomocą Devtools (zakładka Network) lub dowolnego narzędzia typu HTTP Proxy takiego jak Burp czy Charles Proxy. Możesz także skorzystać z darmowego skanera dostępnego na https://securityheaders.com/, podając adres testowanej aplikacji (warto pamiętać o zaznaczeniu opcji „hide results", aby wyniki skanowania nie były widoczne publicznie). Nie będę rozpisywał się na temat każdego z wspomnianych wyżej nagłówków, ale bardzo mocno zachęcam do zapoznania się z informacjami dostępnymi na stronach:
- https://owasp.org/www-project-secure-headers/,
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers.
Temat nagłówków bezpieczeństwa, jak i wszystkich pozostałych, jest naprawdę szalenie ciekawy. Warto zaznajomić się z koncepcją nagłówków i poznać przynajmniej część z nich. Wiedza na temat ich zastosowania, działania oraz błędów w ich implementacji i ich skutkach, pozwoli Ci odkryć bardzo wiele podatności i otworzy przed Tobą ogromny wachlarz nowych możliwości w kontekście testowania bezpieczeństwa. Gwarantuję!
Ujawnienie wersji oprogramowania
Warto zwracać uwagę także na pozostałe nagłówki oraz ich wartości, które przekazywane są w odpowiedziach serwera. Bardzo często, nagłówki takie jak Server czy X-Powered-By zdradzają nazwę i numer wersji oprogramowania zainstalowanego na serwerze. Dzięki takiej informacji atakujący może szybko sprawdzić jakie znane podatności występują w danej wersji oprogramowania i przystąpić do próby ich wykorzystania. Szczególnie, gdy zainstalowane oprogramowanie dawno nie było aktualizowane. Chcąc chronić swoje mieszkanie nie wieszamy przecież przed wejściem kartki z kodem do domofonu oraz marką i rodzajem zamka w drzwiach, prawda?

Podmiana wartości w URL
Kiedy testujesz aplikację webową, zwracaj uwagę na adresy URL oraz to, co się w nich pojawia. Z pewnością nie raz natknąłeś się na adres zawierający fragment przypominający jeden z poniższych:
- testowa-strona.pl/user/24
- testowa-strona.pl/user/janek
- testowa-strona.pl/user/faktury/2020/01/AB-414612.pdf
- testowa-strona.pl/user/124/view
- testowa-strona.pl/admin/uzytkownicy.asp?sid=123321&akcja=edytuj&uid=33
Warto w takiej sytuacji sprawdzać jak zachowa się aplikacja, gdy podmienimy którąś z zawartych w URL-u wartości np: id użytkownika, username. numer pliku lub nazwę akcji itp. Źle zaprojektowana aplikacja, bez odpowiednich mechanizmów autentykacji i autoryzacji umożliwia atakującemu dostęp do danych innych użytkowników lub wykonanie złośliwej akcji. Oczywiście ten aspekt bezpieczeństwa nie sprowadza się tylko do majstrowania przy adresie URL. Temat jest znacznie bardziej rozległy, a podmiana różnych wartości i parametrów, wliczając w to wszelkiego rodzaju wstrzyknięcia (np. SQLi, XSS), może odbywać się nawet bez udziału przeglądarki, np. za pomocą narzędzi takich jak Burp. Jednak w tym artykule kwestie ściśle techniczne pozostawiam na boku. Chciałbym jedynie zaszczepić w Tobie pewną ideę, na bazie której, będziesz mógł kontynuować swój rozwój w kierunku cyberbezpieczeństwa.
Przesyłanie danych protokołem HTTPS
W przypadku stron, modułów i wszelkiego rodzaju mechanizmów przesyłających dane od użytkownika do serwera i z powrotem, bardzo istotną kwestią jest rodzaj wykorzystanego protokołu internetowego. Jeśli testujesz np. formularz rejestracji lub logowania, z pewnością użyty powinien zostać protokół szyfrowany HTTPS, zamiast HTTP.
W przypadku protokołu HTTP i danych nim przesyłanych, istnieje duże ryzyko, że dane zostaną przechwycone podczas ataku „Man in the Middle”, czyli, gdy ktoś niepowołany przekieruje Twoją komunikację do kontrolowanego przez siebie punktu monitorującego, takiego jak HTTP Proxy. Może to być jedno z wspomnianych już w tym artykule narzędzi, takich jak Charles Proxy, Burp, czy Fiddler. Dane przesyłane protokołem HTTP nie są w żaden sposób szyfrowane, więc w przypadku przechwycenia ich przez atakującego, możemy być pewni, że nasze loginy, hasła oraz wszelkie dane jakie zostały wprowadzone w formularzu rejestracji będą widoczne dla atakującego jako zwykły tekst.
Warto jednak pamiętać, że w środowiskach deweloperskich i staging’owych często nie stosuje się protokołu HTTPS, aby ułatwić pracę deweloperom. Dlatego zastosowanie protokołu HTTP zwłaszcza na środowiskach testowych, nie musi z automatu być traktowane jako błąd. Jednak warto sprawdzać czy protokół HTTPS jest stosowany w środowiskach produkcyjnych, szczególnie tam gdzie przesyłane są jakieś dane.
GET them all
Skoro mowa o przesyłaniu danych, to wróćmy jeszcze na moment do adresu URL i parametrów, które się w nim czasem pojawiają. Czy zastanawiałeś się, dlaczego czasami w adresie URL występują parametry, a czasem nie? Powodem może być metoda żądania HTTP, którą dane zostały przesłane do serwera. Podczas testowania aplikacji zwracaj uwagę na to, w jaki sposób przesyłane są dane do serwera. Istnieje wiele metod stosowanych w żądaniach HTTP, takich jak: GET, POST, PUT, DELETE, PATCH, OPTIONS, TRACE itd. W tym akapicie skupimy się na różnicy między metodą GET i POST.
Wbrew pozorom, zarówno jedną jak i drugą metodą jesteśmy w stanie przesłać dane do serwera. Liczy się jednak to, w którym miejscu żądania nasze dane zostaną przesłane. W przypadku metody GET, wszystkie nasze parametry trafiają do linijki żądania, natomiast w przypadku metody POST, będą one przesłane w ciele żądania. Dlaczego to takie istotne? Ano dlatego, że w przypadku przesyłania danych protokołem HTTPS, parametry przekazywane w ciele żądania będą zaszyfrowane. Natomiast w przypadku wysłania ich w linijce żądania będą zapisane plain textem.
Wyobraźmy sobie sytuację, w której mamy formularz rejestracji. Użytkownik rejestrując się, wypełnia wszystkie pola, następnie klika przycisk „Wyślij”. Jeśli deweloper do wysłania formularza zastosował metodę GET wszystkie dane użytkownika zostaną przesłane w linijce (adresie) żądania zamiast w ciele żądania. Więc nawet jeśli żądanie będzie przesłane szyfrowanym protokołem HTTPS, to dane wprowadzone przez użytkownika i tak pozostaną zapisane czystym tekstem. Ponadto, większa część serwerów domyślnie zapisuje logi, więc nasze dane, przesłane takim żądaniem, będą widoczne w logach na danym serwerze w postaci czystego tekstu.
W nieco bardziej pesymistycznym scenariuszu, który zakłada nieodpowiednią konfigurację nagłówka Referrer-Policy, adres URL z naszymi danymi może zostać przekazany do zewnętrznego serwera w nagłówku Referer. Dlatego sprawdzaj jakimi metodami przesyłane są dane z różnego rodzaju formularzy.
Pisownia nazw metod HTTP ma znaczenie
Podczas testowania API aplikacji, pamiętaj, że zapis nazw metod HTTP ma znaczenie. Jeśli dla przykładu, metoda DELETE nie jest dozwolona dla danego endpointu. Sprawdź jak zachowa się aplikacja, gdy użyjesz zapisu delete, DELete, czy dElEte. Może okazać się, że tak skonstruowana nazwa metody zostanie obsłużona. Warto poświęcić kilka minut na sprawdzenie tej kwestii, zwłaszcza, że nie wymaga to zbyt wiele wysiłku.
Mechanizmy utrudniające ataki typu brute-force
Testując formularze logowania, zwracaj uwagę, jak zachowuje się aplikacja po wielokrotnym wprowadzeniu nieprawidłowych danych. Dobrze zaprojektowana aplikacja nie pozwoli na przeprowadzenie zmasowanego ataku w celu odgadnięcia hasła. Dla zwykłego użytkownika manualne wprowadzenie nawet kilkunastu haseł w ciągu jednej minuty może być trudne. Dla zautomatyzowanego narzędzia takiego jak Hydra, ZAP czy Burp, przesłanie nawet kilkuset żądań na minutę z różnymi hasłami nie będzie stanowić większego problemu. Dlatego ważne jest, aby proces logowania był odpowiednio zabezpieczony.
Różne serwisy stosują różne sposoby zabezpieczania się przed tego typu atakami. Jedne blokują adres IP atakującego, inne blokują konto użytkownika (na określony czas lub na stałe, np. w przypadku banków). Oba sposoby mają pewne wady. Pierwszy jest stosunkowo łatwy do obejścia za pomocą serwerów proxy. Drugi — w skrajnych przypadkach, może przyczynić się do unieruchomienia większości kont w całym serwisie.
Jednym ze skuteczniejszych sposobów utrudniających ataki brute-force jest mechanizm CAPTCHA. Wymusza on przesłanie dodatkowego kodu (lub wskazanie odpowiednich obrazków itp.), który generowany jest na nowo, przy każdej próbie wysłania kolejnego żądania. Niestety nawet i ten mechanizm został jakiś czas temu złamany.
Możliwe zatem, że złoty środek póki co nie istnieje, jednak warto rozważyć zastosowanie mechanizmu captcha i/lub mechanizmu odrzucającego żądania do serwera przez np. 30 minut po trzech nieudanych próbach logowania. Z pewnością wydłuży to wielokrotnie potencjalny czas złamania hasła.
Ciasteczka i sesje
Gdy użytkownik loguje się do serwisu internetowego, w jego przeglądarce zapisywane są informacje (tzw ciasteczka/cookies) dotyczące jego preferencje, zachowań i danych usług zewnętrznych, takich jak Google Analytics itd. Jest też zapisywana informacja o numerze jego sesji. Dzięki niej użytkownik może np. zamknąć stronę, a następnie ponownie ją otworzyć, pozostając wciąż zalogowanym.
Nazwy ciastek sesyjnych mogą być różne, w zależności od serwisu, użytej technologii i pomysłu dewelopera, jednak najczęściej zawierają w swojej nazwie takie frazy jak session, SID, SSID, SESID, SESSID itp. Testując kwestie bezpieczeństwa związane z sesją, sprawdzaj czy numer sesji może być przewidywalny. Możesz to zweryfikować logując się i wylogowując kilka razy z rzędu, sprawdzając przy tym każdorazowo numery sesji i porównując je ze sobą. Oczywiście testując w ten sposób, wychwycisz tylko trywialne przypadki, w których numer sesji zmienia się w oczywisty sposób, np wzrasta o jeden itd.
Aby zweryfikować losowość numerów sesji warto skorzystać z modułu Sequencer w programie Burp. Więcej informacji na ten temat znajdziesz tutaj: https://portswigger.net/burp/documentation/desktop/tools/sequencer/getting-started. Dzięki powyższemu modułowi, przeanalizujesz losowość nie tylko numerów sesji ale także różnego rodzaju danych takich jak tokeny resetowania hasła, tokeny CSRF itp. Jeśli numer sesji jest przewidywalny, atakujący na podstawie obserwacji, mógłby odgadnąć numer sesji innego użytkownika, dzięki czemu, byłby w stanie uzyskać dostęp do cudzego konta bez znajomości jego danych logowania, podmieniając tylko wartość swojego ciasteczka sesyjnego.
Kolejną kwestią jaką warto testować w kontekście sesji użytkownika jest jej żywotność. Numer sesji mimo, że jest zapisywany w pamięci przeglądarki użytkownika (klienta), tak naprawdę pochodzi z serwera. W przeglądarce użytkownika służy on jako „dowód osobisty”, którym przedstawiamy się serwerowi. Dzięki niemu serwer wie, że jesteśmy uprawnioną osobą do uzyskania dostępu do danej sesji. Prawidłowo działająca aplikacja w momencie wylogowania użytkownika powinna usunąć numer jego sesji, a przy kolejnym logowaniu — utworzyć nowy. Dzięki takiemu rozwiązaniu, nawet w przypadku wykradnięcia ciastka sesyjnego, po wylogowaniu się użytkownika, atakujący nie będzie w stanie uzyskać dostępu do konta ofiary.
Aby sprawdzić czy sesja zakończona jest nie tylko po stronie klienta, ale także po stronie serwera wykonaj następujące kroki:
- Zaloguj się na swoje konto
- Odszukaj swoje ciasteczko sesyjne (za pomocą Devtools w zakładka Application w sekcja cookies lub dowolnego innego narzędzia do edycji ciasteczek np. dodatku do Chrome - EditThisCookie),
- Skopiuj jego nazwę i wartość,
- Wyloguj się,
- Otwórz inną przeglądarkę lub nową kartę w trybie prywatnym,
- Przejdź na stronę testowanego serwisu,
- Utwórz ciasteczko używając skopiowanej wcześniej nazwy i wartości,
- Odśwież stronę.
- Jeśli po odświeżeniu strony okaże się, że jesteś zalogowany, oznaczać to będzie, że sesja nie jest ubijana po stronie serwera.
Warto także, sprawdzić czy po wylogowaniu się użytkownika, możliwe jest cofnięcie się do poprzednich stron za pomocą przycisków wstecz. Jeśli po wylogowaniu, jesteś w stanie zobaczyć zawartość poprzednich stron — jest to błąd, w wyniku którego niepowołana osoba mogłaby cofnąć się do poprzednich stron, uzyskując przez to dostęp do poufnych informacji. Prawidłowo działający mechanizm powinien wyświetlić ekran logowania, uniemożliwiając zobaczenie treści dostępnych przed wylogowaniem.
Przy okazji tematu ciasteczek warto wspomnieć takżę kwestię flag, które mogą być do nich przypisane. Ważne jest, aby ciasteczka zawierające ważne z punktu widzenia bezpieczeństwa dane, takie jak tokeny czy numery sesji, posiadały przynajmniej dwie flagi: HttpOnly oraz Secure. Pierwsza z nich nie pozwala na dostęp do ciasteczka skryptom, dzięki czemu w przypadku podatności XSS atakujący nie będzie w stanie wyciągnąć wartości ciasteczka za pomocą JavaScriptu. Druga nie pozwoli na przesłanie ciasteczka niezabezpieczonym protokołem HTTP. Aby sprawdzić czy ciasteczko posiada odpowiednią flagę przejdź do Devtools > Application > Cookies. Tam przy konkretnym ciasteczku sprawdź kolumny HttpOnly oraz Secure. Więcej ciekawych informacji na temat flag znajdziesz na:
https://sekurak.pl/flaga-cookie-httponly/, https://owasp.org/www-community/controls/SecureFlag
https://sekurak.pl/flaga-cookies-samesite-jak-dziala-i-przed-czym-zapewnia-ochrone/
Sanityzacja
Testując wszelkiego rodzaju formularze, sprawdzaj jak przetwarzane są Twoje dane wejściowe. Dobrze zaprojektowana aplikacja nie pozwoli na przedostanie się do niej niebezpiecznego ciągu znaków, który mógłby być zinterpretowany jako część kodu, a nie dane pochodzące od użytkownika.
Przykładowo, jako imię w formularzu rejestracji podaj <s>Test</s>. Jeśli po zarejestrowaniu się w polu Twojego imienia pojawił się przekreślony napis Test, oznacza to, że aplikacja w nieoczekiwany sposób zinterpretowała wprowadzony przez Ciebie ciąg znaków. W takiej sytuacji potencjalny atakujący może spróbować także przemycić nie tylko znaczniki HTML, ale także kod javascript czy fragment zapytania SQL. Dlatego bardzo ważne jest zastosowanie odpowiednich mechanizmów (sanityzujących), które rozpoznają potencjalnie niebezpieczne znaki lub fragmenty złośliwego kodu i go zneutralizują. Tak, aby nie przedostał się do aplikacji.
Niestety, bardzo często brakuje takich mechanizmów, co może prowadzić nawet do całkowitego przejęcia kontroli nad aplikacją lub wyciągnięcia z niej wszystkich danych. Dlatego tak istotne jest testowanie tego typu podatności.
Jednocześnie należy pamiętać, że tego typu ingerencja w aplikację może być bardzo poważnym nadużyciem lub złamaniem prawa. Dlatego przed testami tego typu upewnij się, czy Twój klient wyraził na nie zgodę (najlepiej pisemną).
Warto zapoznać się także z bardzo ciekawym artykułem na temat podatności w samym mechanizmie sanityzacji dostępnym pod adresem https://research.securitum.com/dompurify-bypass-using-mxss/
Podsumowanie
Przedstawiony przeze mnie zbiór pomysłów i dobrych praktyk, to tylko bardzo mały wycinek tego, w jaki sposób można podejść do testowania bezpieczeństwa. Mam nadzieję, że zaproponowane przeze mnie rady przydadzą Ci się w codziennej pracy i stawianiu pierwszych kroków w testowaniu bezpieczeństwa.
Jak wspomniałem, celem tego artykułu, było przedstawienie sytuacji z punktu widzenia testera manualnego, który chce rozwijać się w kierunku cyberbezpieczeństwa. Temat bezpieczeństwa jest ogromny i zdecydowanie bardziej złożony niż został przedstawiony przeze mnie w powyższym artykule. Dlatego traktuj go jako zajawkę i zachętę do dalszego rozwoju.
Jeśli dotrwałeś do tego momentu, dziękuję Ci za cierpliwość i wytrwałość oraz życzę Ci sukcesów w dalszej karierze w cyberbezpieczeństwe. Jeśli spodobał Ci się mój artykuł i chciałbyś, abym napisał drugą jego część — udostępnij go i napisz komentarz.


